
- Published on
Scaling a Telehealth Startup - One Year Later
It's been quite the year! Happy to report we've survived a few big PR pushes, a prescription renewal process, shipping delays, product features, and more.
Looking Back
We had a lot of work to do last year. A Mongo database that didn't synch with our payment processor or CRM being the primary problem. The launch was breakneck speed and the backend lead developer/architect wasn't very forward thinking.
System Level "Don't Repeat Yourself"
We use Stripe for three main things -
- Payment gateway
- Recurrence provider
- Subscription datastore
Customers that join our service would be written prescriptions that ultimately would be registered on Stripe as Stripe Subscriptions. However, the nature of our treatments require quite a lot of high touch customer engagement - customers often pause, switch, add treatments.
The backend developer I mentioned built a Subscription and Customer collection in his Mongo database that reflected Customer and Subscription in Stripe. When the Stripe info was updated by other nontechnical members of the team, the Mongo database didn't always update. So Subscription data would become stale - it was very hard to understand which repository should be considered the source of truth!
This was the biggest headache to unravel - and Stripe x Mongo wasn't the only issue along these lines.
- Prescriptions would be written for customers, but which Prescriptions are "active" (Customer has indicated that they want to keep paying and filling on a recurring cadence)?
- Our CRM kept its own view of Customer Profile and attributes, including products. Same problem here - this info became stale as well. Even worse, the CRM had its own "recurrence engine" and would send out "your refill is coming up!" emails based on its internal clock, not Stripe's. So if a delivery date change came into Stripe, our CRM would be out of sync.
Smoothing Out The Wrinkles
Clearly this DRY violation had to stop. Winners of the "system of record" challenge needed to be declared and the others needed to reduce their duplicative data stores.
- Stripe would be system of record for...
- Payment info
- Billing Address
- Actively refilling prescriptions (you may have more on file, but prescriptions are a requirement for payment and shipping, not indicative of current customer preference for what they actively want fulfilled)
- Our backend healthcare API vendor (Capable Health, more to come on them) would be the system of record for...
- Shipping Address
- Patient Medical Background
- Prescriptions on File
- Our CRM would be system of record for...
- Phone number / email (well, email is kind of a primary key, but you know)
How do you eat a horse?
One bite at a time. It took months to fix this up. I started by introducing a Postgres Database on the platform as a service Render. Render's Postgres implementation is top notch. Nightly backups, read only replicas at a push of a button, and much more.
I created & migrated customer records and a "product registry" in Postgres. The customer table at this point was very skinny - email and a bunch of pseudo-foreign keys to the disparate systems. One could look up a customer and fetch their Stripe info via their Stripe Customer id, Prescription info via another id, and so on.
The "product registry" was a similar idea. For any product we offered, keep track of the system keys (fulfillment, prescription, stripe price ids, etc).
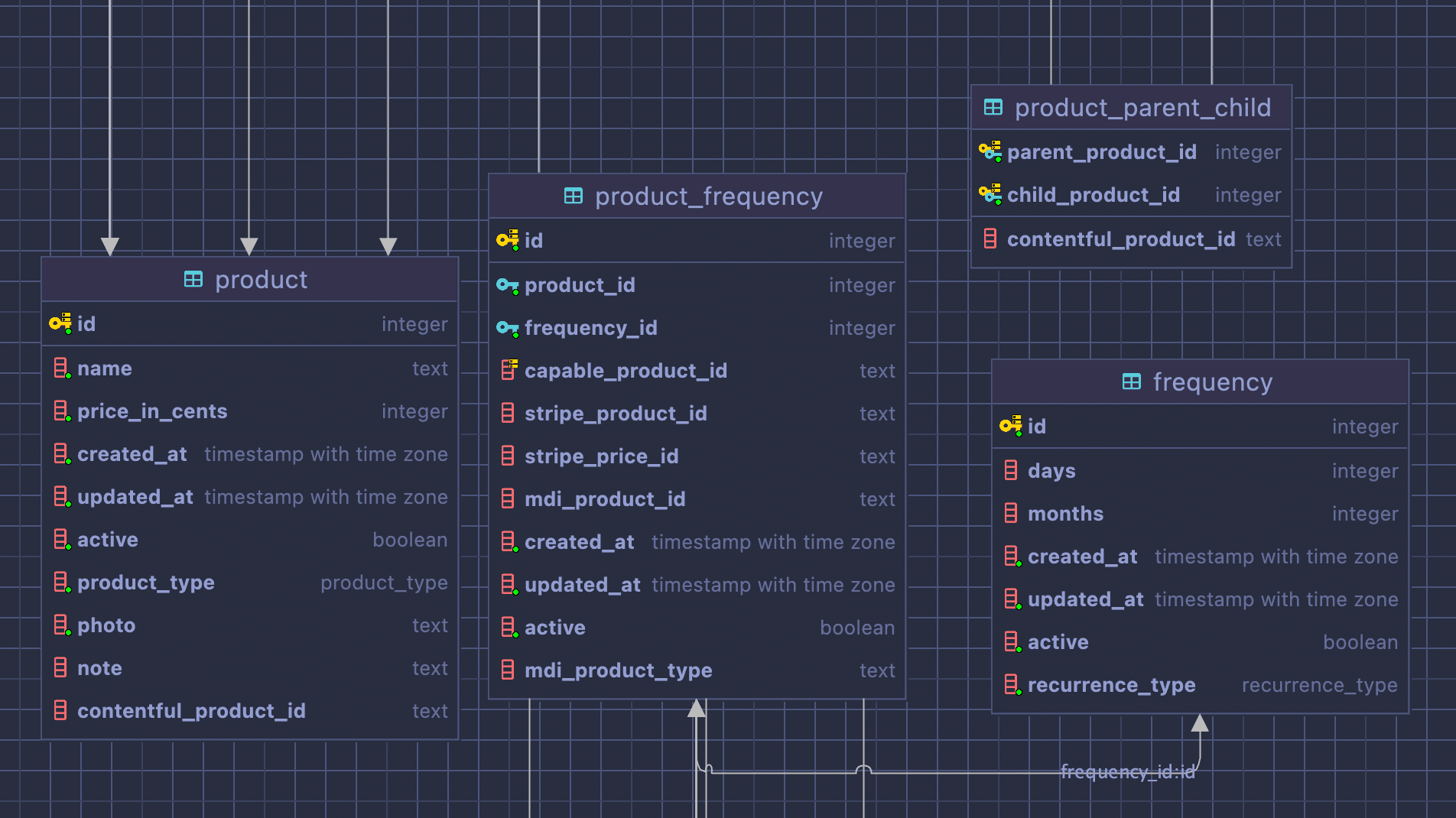
Over time we weeded out products that had been created and used in the disparate systems that were duplicative or didn't fit into our system architecture, migrating customers onto the supported configurations instead.
Renewal
How do you ensure a prescription based platform dies in the first year? Easy - don't renew anyone's prescriptions! Fortunately, we had an easy solution that we delivered on time for our first customer renewals.
We built this out using Render's cron functionality. Nightly we simply check for due-to-expire or zero fill prescriptions. We do a little bit of shuffling via a tracker table to ensure that we start sending a renewal drip campaign at the right time. One job to find prescriptions in need of renewal that writes to the tracker table, another to read off the tracker table and kick off the process with our CRM.
Migrating From Capable Health
Towards the end of January we learned of the worst possible news - Capable Health was shutting down. Being so deeply embedded with them - it would be very challenging to migrate out. But we don't do these things because they're easy :)
The team made a plan and got to work!
A Clockwork App
The renewal job was an inspiration for our system design. We connect several back end vendor systems - and if we do it ourselves, we'll need to be resilient to failures, give ourselves the tools to easily resend, and troubleshoot when things go wrong. A queue, basically. But why bring in more technology than necessary? Choose boring tech. If we think of a database table with a status column as a queue, for the few hundred rows we add daily, throughput is low enough that's all we'll ever need.
Our system architecture at this point reminds me of the old "Clockwork" Magic: The Gathering cards.

Our guiding principles:
- Synchronous webhooks should merely record the event and any necessary attributes - a prescription was written, a card was charged, etc.
- Async cron jobs roll through the queue looking for work, then pump that work into the next step. Any failure puts them into a
MANUAL_INTERVENTIONdead letter queue for further troubleshooting.
Authentication
The trickiest part to get right was authentication. Capable's Cognito held all of our ~15-20k registered customers. AWS doesn't allow you to transfer users cross accounts, but it does provide a method to plug in a Migrator Lambda. So we got this up and running to allow customers to seamlessly bleed into our new Cognito first while we continued working on the rest of the systems.
We migrated 30% of our most active customers using this method without those customers even knowing it happened - upon successful authentication their credentials automatically move over to our AWS account's Cognito.
Data Migration
We initially didn't know how much time we had, and whether we'd receive any data dumps. We also couldn't go dark for a single day - revenue is top priority for an early startup and we couldn't miss a beat (in fact, we had a massive flux of inbound customers due to a great article about is in the New York Times during this transition!)
We created data migrators again using Render's cron functionality. Every night, our migrator would wake up and either save off all the data around a particular entity (customer, prescription, etc) or save the most recent values (when the entity is more or less immutable).
We stood this up and kept it running nightly, allowing us to breathe easy knowing when we were ready with our big bang switchover we'd have the latest and greatest data ready to go (even being able to run this on demand!)
On deploy day, I had a series of SQL scripts ready to copy these Capable backup tables into our going forward schema, smoketested against a recent Postgres backup and ready to run.
Deploy Day
The true test! After about a dozen last minute bugfixes, we took down the site at 2pm cst (we made a maintenance page that locked you in till the deploy was complete). We deployed and migrated, then ran the ETL and brought the site back up. After 2 months of work, the resulting deploy went off with hardly a hitch or impact to revenue. The site was only down for about 45 minutes.
What We Gained
Our data! Thankfully, true ownership over both our data and our processes. Capable was great for the relationships and experience, but too many fingers in the pot simply makes software difficult to trace.
Internal Tooling
Metabase + Retool work wonders together. We're still building it out, but super excited to see where things are headed. I've built internal operational dashboards to shine a light on delayed shipments, prescription issues, and other issues with our systems talking to our vendors.
I'll write a followup on internal tooling at some point, this journal entry is getting pretty long. But it feels like we've turned a corner and we're ready for the next big thing!
Onward!